안녕하세요
K-IN 입니다.

대규모 데이터 처리를 위해 스프링 배치(Spring Batch) 를 자주 이용했을 것입니다.
이번 시간에는 코틀린을 이용해 스프링 배치 예시를 만들면서 스프링 배치가 코틀린에서 어떻게 구현되는지 알아보겠습니다.
특기할 점은 스프링 배치 공식 문서에는 코틀린 버전으로 설명을 제공하고 있지 않습니다.
이 예시는 Java 로 구성된 공식 문서의 설명을 Kotlin 언어로 풀어내고 있어 코틀린을 처음 접하신 분들이 Spring Batch 를 구현하는 허들을 낮추어주는 효용이 있습니다.
TLDR; 코드 제공
이번 과정에서 다룬 내용은 Bitbucket 을 통해서 다운로드 할 수 있습니다.
링크로 접근하셔서 clone 버튼을 눌러주세요.

https://bitbucket.org/kinstory/kotlin-spring-batch/src/main/
Bitbucket
bitbucket.org
스프링 배치(Spring Batch)의 목적
Spring Batch 는 대규모 데이터 처리를 위한 프레임워크입니다.
일괄 처리 작업을 효과적으로 구현할 수 있도록 합니다.
아래의 작업을 할때 유용합니다.
- CSV 파일 처리: 대량의 데이터가 포함된 CSV 파일을 읽어와 데이터를 가공하거나 데이터베이스에 저장합니다.
- 데이터베이스 마이그레이션: 데이터베이스 스키마의 변경이나 데이터 이관이 필요한 경우 사용됩니다.
- 이메일 발송: 대량의 이메일을 보내는 작업에 유용합니다. 예시로 회원 정보를 조회하고 이메일을 작성하여 회원들에게 일괄적으로 발송.
- 배치 프로세싱을 통한 데이터 정제: 데이터의 정합성을 유지하기 위해 주기적으로 실행되는 작업. 예시, 주문 데이터에서 비정상적인 값이나 중복된 데이터를 제거하거나 수정.
- 파일 처리: 서버에 업로드된 파일을 주기적으로 처리하는 작업. 예시, 업로드된 이미지 파일 중에 특정 조건을 충족하지 않는 파일을 삭제하거나 이동.
- 통계 및 보고서 생성: 주기적으로 데이터를 집계하고 통계를 생성하는 작업. 예시, 일일 매출 통계, 월간 사용자 활동 보고서 생성.
- 외부 API와의 상호 작용: 외부 시스템과의 통합이 필요한 경우 사용. 예시, 외부 API에서 데이터를 가져와서 내부 시스템에서 사용하거나 업데이트.
- 주기적인 데이터 백업: 시스템의 중요한 데이터를 주기적으로 백업하는 작업. 예시, 주기적으로 데이터베이스를 백업하고 안전한 위치에 저장.
프로젝트 구성하기
IntelliJ 를 사용할 경우, New Project 를 통해서 Spring Initializer 를 사용해 프로젝트를 시작할 수 있습니다.
만약, vscode 등의 다른 IDE 를 사용하고 있다면 start.spring.io 에 접속하여 프로젝트를 시작할 수 있습니다.
아래와 같이 따라서 설정합니다.
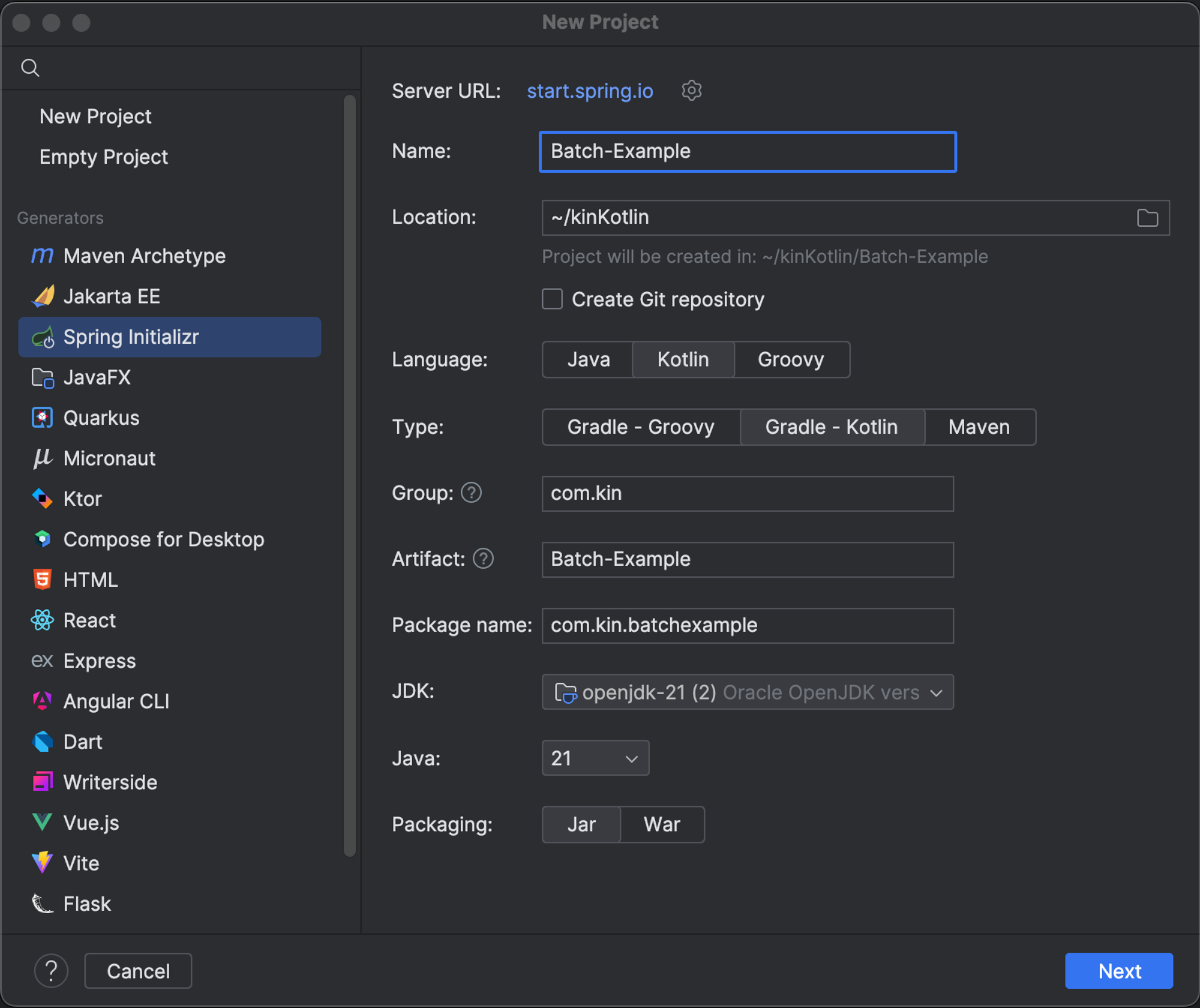

온라인에서 프로젝트를 설정하는 경우 아래와 같이 설정합니다.
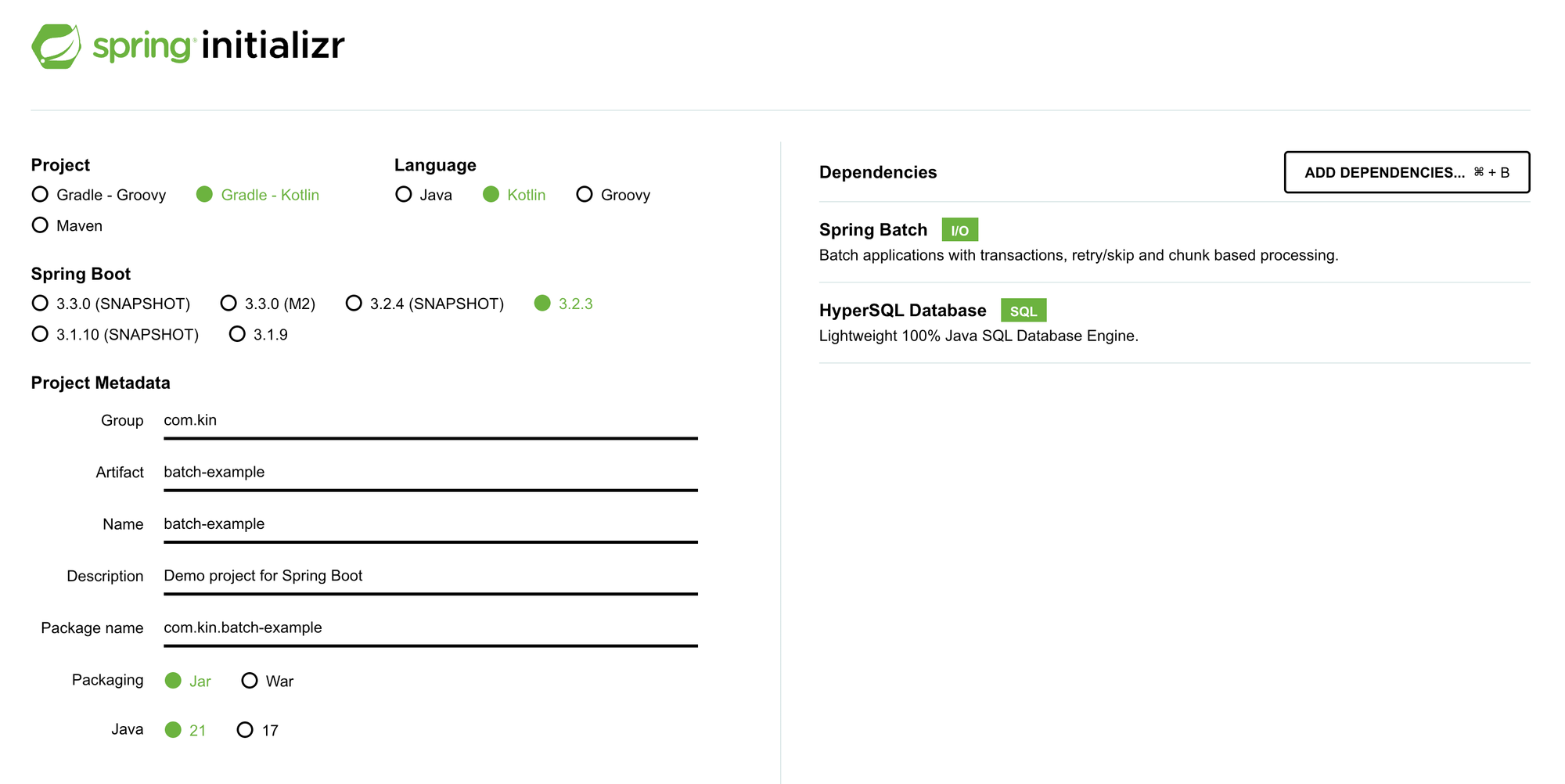
스프링 배치 프로젝트의 흐름 정의 및 구조
여러분이 스프링 배치를 처음 접할 경우 앞서 설명드린 스프링 배치를 구현하는 목적을 달성하기 위해 이 글을 읽고 있을 것입니다.
프로젝트는 다음의 기본적인 구현을 통해서 스프링 배치의 기본적인 개념을 익히는 것이 첫번째 목적이며 두번째 목적은 코틀린 기반으로 스프링 배치 프로젝트를 시작할 때 사용할 수 있는 스켈레톤 코드를 마련하는 것입니다.
이 프로젝트는 다음의 구현을 제공합니다.
- 리소스 폴더의 csv 파일을 읽어들이고 이를 처리 후 인메모리 HSQL 에 저장
- 즉, read → process → write 를 수행하는 Job 을 정의
프로젝트 폴더 구조입니다.
흐름을 잡기 위해서는 폴더 및 파일 배치들을 이해하면 쉽습니다.
-> % tree ./src
./src
├── main
│ ├── kotlin
│ │ └── com
│ │ └── kin
│ │ └── batchexample
│ │ ├── BatchConfiguration.kt
│ │ ├── BatchExampleApplication.kt
│ │ ├── JobCompletionNotificationListener.kt
│ │ ├── Person.kt
│ │ └── PersonItemProcessor.kt
│ └── resources
│ ├── application.properties
│ ├── sample-data.csv
│ └── schema-all.sql
└── test
└── kotlin
└── com
└── kin
└── batchexample
└── BatchExampleApplicationTests.kt
12 directories, 9 files
이프로젝트는 resources 폴더에 정의된 csv 파일을 읽어옵니다.
각 코틀린 소스파일의 역할은 다음과 같습니다.
- Person.kt : csv 파일의 데이터를 초기화하는 데이터 클래스
- PersonItemProcessor.kt : 초기화된 Person 데이터를 처리하는 프로세서 클래스
- JobCompletionNotificationListener.kt : 배치 작업이 완료된 결과를 확인하는 리스너(Listener) 클래스
- BatchConfiguration.kt : 스프링 컨텍스트의 구성을 담당하는 Configuration 클래스
- BatchExampleApplication.kt : 코드를 실행하는 main 함수가 정의된 소스코드
이제 단계별로 시작하겠습니다.
샘플 데이터 복사 및 위치
아래 링크를 방문하여 sample-data.csv 파일과 schema-all.sql 파일을 다운로드 받아서 src/main/resources 폴더에 복사를 합니다.
https://bitbucket.org/kinstory/kotlin-spring-batch/src/main/src/main/resources/
Bitbucket
bitbucket.org
예시 데이터는 성과 이름을 csv 포맷으로 저장한 데이터 파일과 데이터를 저장할 테이블을 생성하는 쿼리입니다.
Jill,Doe
Joe,Doe
Justin,Doe
Jane,Doe
John,DoeDROP TABLE people IF EXISTS;
CREATE TABLE people (
person_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);
비즈니스 클래스를 생성
데이터의 입력과 출력의 형식을 확인할 수 있도록 데이터의 행(row)를 표현하는 코드를 작성해야합니다.
여기서 data 키워드는 데이터 클래스를 정의하기 위해 사용되는 특별한 키워드입니다. java 에서는 record 를 사용합니다.
Person 데이터 클래스의 멤버(firstName, lastName)에 기본값을 공백문자로 설정하였습니다.
왜 기본값을 제공했는지 궁금하다면 아래의 글을 추천드립니다.
2024.03.07 - [프로그래밍/코프링] - 코프링, 코틀린 데이터 클래스와 FlatFileParseException 해결
코프링, 코틀린 데이터 클래스와 FlatFileParseException 해결
안녕하세요 K-IN 입니다. FlatFileItemReader 이란? CSV 파일을 리소스 폴더에 두고 읽어오기 위해 필요한 클래스입니다. 이 클래스를 통해서 Dto 와 같이 데이터 클래스를 초기화할 수 있습니다. 예를들
k-in.tistory.com
package com.kin.batchexample
data class Person(var firstName: String = "", var lastName: String = "") {
}
data 키워드와 관련해서 아래의 글을 읽어보시길 추천드립니다.
2024.03.07 - [프로그래밍/코틀린] - 코틀린, data 키워드와 데이터 클래스
코틀린, data 키워드와 데이터 클래스
안녕하세요 K-IN 입니다. 코틀린에 대해서 알아보겠습니다. 전체 강의 목록은 아래의 링크를 클릭해주세요. 2024.01.31 - [코틀린] - K000. 코틀린 시리즈 (연재물) K000. 코틀린 시리즈 (연재물) 안녕하
k-in.tistory.com
중간 처리자 구현
배치 처리의 일반적인 패러다임은 데이터를 수집하고, 변환한 다음에 다른 곳으로 파이프하는 것입니다.
이 예시에서는 이름을 대문자로 변환하는 간단한 변환기를 작성해서 적용합니다.
이를 위해 PersonItemProcessor 클래스를 추가하고 ItemProcessor 인터페이스를 구현하며 process 메소드를 override 합니다.
process 는 각 데이터의 행이 초기화된 Person 객체를 입력으로하고 대문자로 변환 처리를 한 결과를 반환합니다.
이 예시에서는 Person 객체를 입력받아 대문자로 처리한 Person 객체를 리턴하지만 다른 데이터 타입을 리턴해도됩니다.
package com.kin.batchexample
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.springframework.batch.item.ItemProcessor
import java.util.*
class PersonItemProcessor : ItemProcessor<Person, Person> {
companion object {
private val log: Logger = LoggerFactory.getLogger(PersonItemProcessor::class.java)
}
override fun process(person: Person): Person {
val firstName = person.firstName.uppercase(Locale.getDefault())
val lastName = person.lastName.uppercase(Locale.getDefault())
val transformedPerson = Person(firstName, lastName)
log.info("Converting ($person) into ($transformedPerson)")
return transformedPerson
}
}
위 예시에서 로깅을 위한 Logger 객체를 컴패니언 객체(companion object)로 구현한 것을 볼 수 있습니다.
컴패니언 객체와 관련한 글을 읽어 보시는 것을 추천드립니다.
2024.03.07 - [프로그래밍/코틀린] - 코틀린, 정적 멤버와 컴패니언 객체(companion object)
코틀린, 정적 멤버와 컴패니언 객체(companion object)
안녕하세요 K-IN 입니다. 코틀린에 대해서 알아보겠습니다. 전체 강의 목록은 아래의 링크를 클릭해주세요. 2024.01.31 - [코틀린] - K000. 코틀린 시리즈 (연재물) K000. 코틀린 시리즈 (연재물) 안녕하
k-in.tistory.com
배치 Job 구현
다음으로 실제 배치 작업을 구현해보겠습니다.
Spring Batch 는 사용자 정의 코드를 작성할 필요성을 줄여주는 유틸리티 클래스를 제공합니다.
이에 개발자는 비즈니스 로직에 집중할 수 있습니다.
BatchConfiguration 클래스를 생성합니다. 메모리 기반 데이터베이스를 사용하므로 완료되면 데이터가 사라집니다. Bean 을 통해서 스프링 컨테이너에 reader, writer, processor 를 정의합니다.
스프링 배치는 Job 을 실행하기 위한 여러방식을 제공합니다.
- Classpath 스캐닝 방식: 클래스 패스에서 Job 을 스캔하여 자동으로 등록하는 방식을 제공합니다.
- XML 설정 파일 : XML 설정 파일을 통해서 Job 을 등록하고 설정
- Programmatic Job 등록: 프로그래밍 방식으로 Job 을 등록
이 예시에서는 Classpath 스캐닝 방식을 사용합니다. 아래의 예시에서 Job 을 리턴하는 함수는 importUserJob 메소드입니다.
@SpringBootApplication 어노테이션을 사용하는 경우 @ComponentScan 이 활성화되며 importUserJob 를 스캔합니다.
단, Bean 어노테이션을 설정해야 자동으로 실행이됩니다.
Bean 어노테이션이 없다면 importUserJob 를 호출해야만 동작하므로 주의합니다. 즉, 스캐닝되어 인식은 되나 실행은 되지 않습니다.
코드를 설명하면 다음과 같습니다.
- reader: sampe-data.csv 파일을 Classpath 스캐닝을 통해 가져와서 한 라인 씩 읽어들입니다.
- processor: PersonItemProcessor 를 리턴합니다.
- writer: 처리한 결과를 HSQL 에 insert 합니다.
- importUserJob: Job 을 정의합니다. 작업이 완료될 경우 JobCompletionNotificationListener 를 호출하도록 하며 step1 빈 메소드를 실행하도록 합니다.
- step1: reader → processor → writer 스텝을 구성합니다. 처리되는 항목의 갯수를 조정하는 chunk 사이즈를 조절 할 수 있으며 3으로 설정되었습니다.
package com.kin.batchexample
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
@Configuration
class BatchConfiguration {
@Bean
fun reader(): FlatFileItemReader<Person> {
return FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(ClassPathResource("sample-data.csv"))
.delimited()
.names("firstName", "lastName")
.targetType(Person::class.java)
.build()
}
@Bean
fun processor(): PersonItemProcessor {
return PersonItemProcessor()
}
@Bean
fun writer(dataSource: DataSource): JdbcBatchItemWriter<Person> {
return JdbcBatchItemWriterBuilder<Person>()
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)")
.dataSource(dataSource)
.beanMapped()
.build()
}
@Bean
fun importUserJob(
jobRepository: JobRepository,
step1: Step,
listener: JobCompletionNotificationListener): Job {
return JobBuilder("importUserJob", jobRepository)
.listener(listener)
.start(step1)
.build()
}
@Bean
fun step1(
jobRepository: JobRepository,
transactionManager: DataSourceTransactionManager,
reader: FlatFileItemReader<Person>,
processor: PersonItemProcessor,
writer: JdbcBatchItemWriter<Person>
): Step {
return StepBuilder("step1", jobRepository)
.chunk<Person, Person>(3, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
// .transactionManager(transactionManager)
.build()
}
}
위 예시에서 사용된 Configuration 어노테이션에 대해서 궁금하다면 아래의 글을 추천드립니다.
2024.03.07 - [프로그래밍/코프링] - 코프링, 스프링 @Configuration 어노테이션(Annotations)
코프링, 스프링 @Configuration 어노테이션(Annotations)
안녕하세요 K-IN 입니다. @Configuration 어노테이션 Configuration 어노테이션은 해당 클래스가 스프링 컨텍스트의 구성(configuration)을 담당하는 클래스임을 나타냅니다. 스프링에서 Java 기반 설정을 지
k-in.tistory.com
또한, 위 예시에서 사용된 Bean 어노테이션에 대해서 궁금하다면 아래의 글을 추천드립니다.
2024.03.07 - [프로그래밍/코프링] - 코프링, 스프링 @Bean 어노테이션(Annotations)
코프링, 스프링 @Bean 어노테이션(Annotations)
안녕하세요 K-IN 입니다. @Bean 어노테이션 Bean 어노테이션은 스프링 프레임워크에서 빈(Bean) 객체를 정의하는데 사용됩니다. 빈(bean)은 스프링 애플리케이션 컨텍스트에 등록되어 관리되는 객체이
k-in.tistory.com
작업 완료 리스터 구현
정의한 배치 작업이 완료되면 이를 리스팅하는 리스너를 추가해서 결과를 확인할 수 있습니다.
결과는 인메모리 HSQL 에 저장되므로 JdbcTemplate 이 필요합니다.
의존성 주입을 위해 생성자 인자로 정의하거나 Autowired 어노테이션을 통해 의존성 주입을 할 수 있습니다.
afterJob 메소드를 오버라이드하여 작업 종료 이벤트를 감지하고 HSQL 에서 데이터를 읽고 이를 출력하여 변환이 잘되었는지 검증할 수 있습니다.
package com.kin.batchexample
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.springframework.batch.core.JobExecution
import org.springframework.batch.core.JobExecutionListener
import org.springframework.batch.core.repository.JobRepository
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.jdbc.core.JdbcTemplate
import org.springframework.stereotype.Component
import org.springframework.jdbc.core.DataClassRowMapper;
@Component
class JobCompletionNotificationListener
//(
//private val jdbcTemplate: JdbcTemplate
//)
: JobExecutionListener {
@Autowired
private lateinit var jdbcTemplate: JdbcTemplate
companion object {
private val log: Logger = LoggerFactory.getLogger(PersonItemProcessor::class.java)
}
override fun afterJob(jobExecution: JobExecution) {
if (jobExecution.status == org.springframework.batch.core.BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results")
jdbcTemplate.query(
"SELECT first_name, last_name FROM people",
DataClassRowMapper(Person::class.java)
).forEach { person -> log.info("Found <$person> in the database.") }
}
}
}
실행하기
여기까지 고생하셨습니다.
스프링 배치 작업을 실행하기 위해서는 main 메소드를 통해서 실행하여야 합니다.
스프링 배치는 웹 앱이나 WAR 파일 내에 임베딩될 수 있지만 간단하게 standalone 어플리케이션 예시를 통해 실행하겠습니다.
EnableBatchProcessing 는 스프링 배치 자동 구성을 활성화하였습니다. 그러나, 스프링 3.0 부터는 해당 어노테이션이 필요하지 않습니다.
package com.kin.batchexample
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing
import org.springframework.boot.SpringApplication
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
//@EnableBatchProcessing
@SpringBootApplication
class BatchExampleApplication
fun main(args: Array<String>) {
runApplication<BatchExampleApplication>(*args)
}
IDE 가 아닌 빌드파일을 실행하려면 프로젝트 루트에서 아래의 명령어들을 실행합니다.
./gradlew build
java -jar build/libs/Batch-Example-0.0.1-SNAPSHOT.jar
또는 곧바로 실행할 수 있습니다.
./gradlew bootRun
실행 결과는 아래와 같습니다.
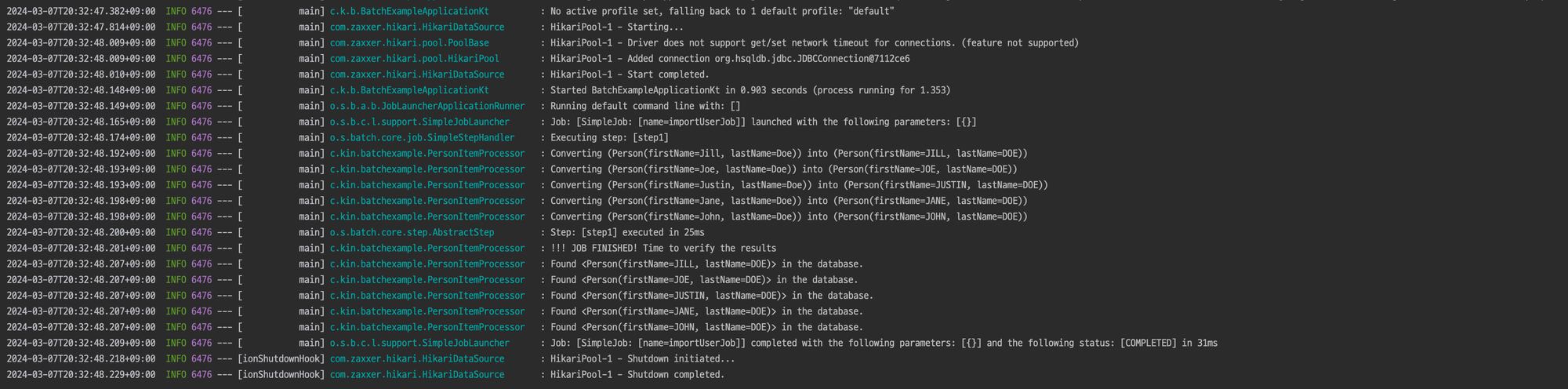
맺음말
제공드린 비트버킷 코드를 통해 여러분이 원하는대로 코드를 변경해서 사용할 수 있습니다.
불필요한 시행착오는 줄이고 여러분이 원하는 비즈니스 로직 구성에 집중할 수 있기를 기원합니다.
이상입니다.
K-IN 올림.
참고
'프로그래밍 > 코프링' 카테고리의 다른 글
| 코프링, 성공적인 서비스를 위한 멀티 모듈 프로젝트 구성 (Feat. 코틀린 Gradle) (57) | 2024.04.05 |
|---|---|
| 코프링, 스프링 부트(Spring Boot) 코틀린으로 배워보자! (68) | 2024.03.20 |
| 코프링, 코틀린 데이터 클래스와 FlatFileParseException 해결 (75) | 2024.03.07 |
| 코프링, 스프링 @Bean 어노테이션(Annotations) (72) | 2024.03.07 |
| 코프링, 스프링 @Configuration 어노테이션(Annotations) (5) | 2024.03.07 |



